




2022年10月17-21日,第28届ACM移动计算与通讯系统大会(MobiCom 2022,CCFA类)在澳大利亚悉尼举行。计算机学院系统软件团队关于泛在计算环境下的利用异构计算资源进行端侧原位训练的论文“Mandheling:Mixed-Precision On-Device DNN Training with DSP Offloading”进行了在线汇报,得到了与会者的高度关注和广泛讨论。
论文图示
在泛在计算环境下,智能化已经成为系统软件的重要基本特征之一,实现智能化的主要途径是训练出高质量的机器学习模型。近年来,相对于在云计算和数据中心上的大规模模型训练,在移动设备本地来训练深度神经网络模型(DNN),即端侧或边缘侧的设备上的原位训练模式(On-DeviceTraining)得到了学术界和工业界的关注。原位训练模式在数据安全隐私保护、网络连接不稳定、恶劣物理环境等场景下的智能任务有其特殊的应用优势,主流的深度学习框架如谷歌的TensorFlow、阿里的MNN均对端侧的DNN训练提供了支持。
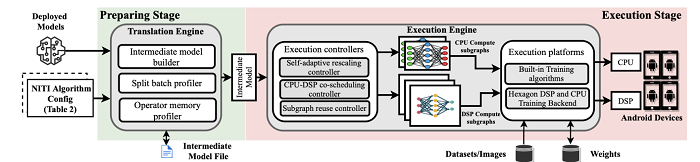
端侧原位训练的主要挑战之一在于端设备资源能力受限。不同于传统方法主要利用CPU和GPU等计算资源,本文提出了对端侧重要的异构计算资源—数字信号处理器(Digital Signal Processor)进行软件定义以支持混合精度训练的分载技术及系统Mandheling。一方面,传统的DNN训练主要在FP32数据格式上执行,但近期研究发现,一些混合精度算法生成的权重和激活若用INT8和INT16等低精度数据格式表示,能够有效降低训练时间资源成本,同时保证收敛精度,如在CIFAR-10上仅损失1.3%。而另一方面,DSP特别适合整数运算,比如INT8矩阵乘法,Hexagon 698 DSP足以在一个周期内执行128次INT8操作。
Mandheling基于“软件定义”的思路,提出了四项创新技术充分发挥了DSP在整数计算中的优势以支持混合精度模型的高效原位训练:(1)提出CPU-DSP协同调度策略以减轻对DSP不友好的算子的开销;(2)提出自适应重伸缩rescaling算法减少反向传播dynamicrescaling的开销;(3)提出batch-splitting算法来提高DSP缓存效率;(4)提出DSP计算子图复用机制以消除DSP上的准备开销。实验结果表明,与TFLite和MNN两个SOTA的端侧DNN训练引擎相比,Mandheling将每个批(batch)的训练时间平均减少了5.5倍,能耗平均减少了8.9倍。在端到端训练任务中,与FP32精度的baseline相比,Mandheling将收敛时间提升了10.7倍,同时能耗降低13.1倍,模型准确率损失仅为2%。
本文的第一作者为2021级博士生徐大亮,指导教师为刘譞哲研究员。值得一提的是,该课题组是国际上最早研究泛在计算环境下原位训练智能系统的团队之一,成果已经连续发表在MobiCom 2018、WWW 2019(中国学者首个WWW最佳论文奖)、MobiSys 2020、WWW 2021、MobiSys 2022等顶级会议上,在与国家电网、中国铁道、KikaTech等的合作中产生了积极的应用效果和影响。
ACM MobiCom是计算机网络系统的顶级学术会议,也是CCF推荐的A类会议。MobiCom 2022收到了314篇投稿,录用56篇,录用率为18%。