




- 14 高校采购信息
- 11 科技成果项目
- 0 创新创业项目
- 0 高校项目需求
融合架构的高时效可扩展大数据分析平台


大数据应用的多样化
- 需要的计算模型、数据模型多样化;
- 目前每类模型需要单独的开源系统来支持(如HDFS、HBase、Neo4j、MongoDB,Flink,Spark,Tensorflow等)。
多系统导致大数据分析平台非常复杂、效率低下。

研究目标:
研究和开发面向新型多计算模型融合架构的、高时效、可扩展的新 一代大数据分析支撑系统与工具平台FAST(Fusion-Architecture, Scalable, Time-efficient big data analysis platform)。
针对目前大数据分析平台复杂、效率低下的痛点,该系统具有三个 方面的优势:首先,这套系统采用融合架构,一方面实现关系、图、键 值、文档等多种数据模型的高效融合,另一方面实现批处理计算、流计 算的深度融合,并可以通过SQL扩展语言来进行多模型的统一查询,实现高效的跨模型查询。其次,对于复杂系统来说,时效性非常重要,这 套系统采用融合架构提高效率是实现高时效的基础,更重要的是,我们 对大数据分析从数据到用户进行了端到端的全栈时效优化。最后,对于 大数据应用来说,系统扩展性非常重要,本系统在资源层、存储层和计 算层进行了全面的扩展性优化。下面在融合架构、高时效和可扩展这三 个方面,分别详细介绍FAST系统的三个主要亮点。
融合架构
FAST系统的第一个亮点是融合架构,我们在技术方面的创新主要包 括多数据模型融合和多计算模型融合两方面。
多数据模型融合:
设计和研发了多模型数据管理与查询引擎,支持关系、图、键值、 文档等多种数据模型,实现了查询解析、查询优化、元数据管理、数据 分布等功能,将多种数据模型进行统一管理和深度融合。同时扩展了SQL语言,通过统一的查询接口支持对关系、键值、图、文档等数据进行独立访问或者跨模型查询。

经过试验,多模型数据融合查询,比Spark 2.3.4的查询时间能平均减少70.7%。目前spark等现有系统还需要手工编程方式来实现跨模型查 询,所以FAST系统在易用性上也表现良好,降低使用门槛,提高开发效率。
多计算模型融合:
在计算层实现了最常见的批处理计算和流计算深度融合,批流融合的核心方法是在系统内部实现批和流的统一表达,批是对有限数据集 的运算,流是对无限数据流的计算,我们设计了UCollection结构对批和 流数据进行统一表达,通过识别的bounded标志,来确定是批、流、或批流融合。有了统一表达,可以开展一系列融合优化来提升系统性能。 并且对上通过Unified API统一用户的批、流接口,实现二者在编程范式上的统一表达。对于批流混合的计算,融合架构系统的查询延迟比Flink 1.4.2能减少57%,吞吐量平均可以提升到6.72倍。

高时效
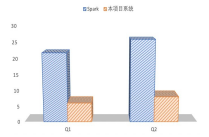
FAST系统的第二个亮点是高时效,即缩短大数据分析的时间消耗, 提高效率。由于大数据分析平台是一个非常复杂的系统,为了做到高时效,系统不能存在性能短板,因此需要对大数据分析的整个过程进行端到端的全栈时效优化。如图中所示,自下而上,需要在多模态存储、批流融合、机器学习、人工操作各层都进行优化。
- 对于多模态存储,面向应用负载和异构硬件特征进行自适应优化;
- 对于批流融合计算,在统一表达基础上,进行系列融合优化技术, 包括DAG优化、迭代优化、部署优化、操作符优化等;
- 在机器学习层面,进行模型优化、消息优化、梯度优化、概率优化 等来提高时效;
- 而且我们也考虑到大数据分析过程中用户人工操作的时效性问题, 通过智能地进行大数据分析方法和模型的推荐,来缩减人工操作的 时间。
可扩展
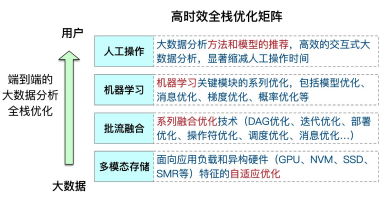
FAST系统的第三个亮点是可扩展,由于大数据应用规模很大,数据增速快,对系统可扩展性的要求非常高,为此我们在系统的资源层、 存储层和计算层进行了全面的扩展性优化。
- 在资源层,系统都部署在云计算的虚拟化资源之上,利用了云计算资源的弹性机制进行系统扩展。并在系统中实现了可伸缩调整模块, 能实时监控软硬件系统的状态,按照应用需求来自适应地进行弹性伸缩。
- 在存储层,分布式存储系统扩展性的关键在于分布式共识和一致性 协议(Raft),因此提出了KV-Raft、vRaft等进行Raft的扩展优化。
- 在计算层,我们扩展了机器学习模型的参数规模,使系统可以支持 到百亿级别的超大规模机器学习模型训练,并且性能方面有明显提 升。
亮点成果:
融合架构大数据分析平台目前已经在阿里巴巴双十一进行示范应用。 从2020年11月10日至11月16日一周的时间,在阿里的生产环境中,研发 的系统一直连续稳定运行,基于淘宝和天猫的实际用户信息进行大数据 分析,综合运用了本系统的存储、计算、机器学习等多个模块的能力, 累计进行了184亿件商品推荐。
同时在双十一期间,基于智能交互向导技术,也面向电子商务应用 的卖家提供了“生意参谋”应用,基于大数据分析,帮助卖家分析产品 销量变化的原因,以及促销的有效手段等。


扫码关注,查看更多科技成果