




- 24 高校采购信息
- 83 科技成果项目
- 0 创新创业项目
- 0 高校项目需求
全文相似性检测系统


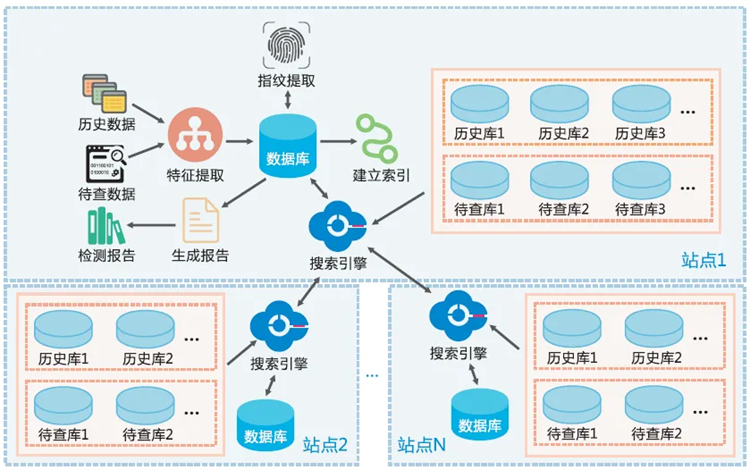
全文相似性检测系统是基于数据挖掘、自然语言处理、机器学习、概率统计等方法,以“特征提取、文本聚类、相似性计算”为核心,在海量文档集中快速、准确、高效地发现相似的文档及相似的内容,检测出项目申请书等材料的抄袭、多次申报和多头申报等现象,在为项目的形式审查提供证据和决策支持,为科研诚信提供有效的检测手段。系统支持全文、图像的相似性检测以及引文甄别等功能。具体核心技术如下:
(1)高容错,高性能的分布式项目全文检索系统
基于科技专业词库、特征库等、对项目全文建立索引,能够对项目的标题、作者、摘要、正文进行模糊检索、分类搜索、高级复合搜索、全文检索、图片内容检索、跨库检索、多语言检索、多格式文档检索、自定义时间检索等。
实现分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索;同时,支持不同粒度的多级字词句索引和文档索引。
实现在搜索结果集中,标识关键词,用特殊的字体及颜色和其他文字进行区别,查询者可在查询结果片断中一目了然的看到关键词出现的位置。
支持一对一相似性检测和一对多相似性检测并生成检测报告,支持报告模板格式可配置、支持检测报告的批量导出。
(2)引文甄别
支持引文的作者、题名、其他题名信息[文献类型标识/文献载体标识]、出版地、出版者、出版年、引文页码[引用日期]等主要实体信息甄别功能。
(3)图像相似性检查
支持从word、pdf格式的申请书中提取图像,快速、准确地检索内容相似的图像,支持上传单独的图像进行检测,支持以项目书为单位进行图像检测,支持对检测结果按各种条件的查询,支持相似图像的证据溯源。
(4)相似性检查服务接口
提供用户认证接口、提供相似性实时检测API、检测完成状态获取接口API、检测报告生成和下载API、提供WEB界面,支持手动实施临时的检测服务。
(5)系统快速准确
系统支持word、txt和pdf格式的检测:实现pdf格式的提取成功率达到99.99%,pdf格式的章节划分成功率达到99%,对word和txt指标要求达到100%。提取速度达到每日30万篇。实现对百万级记录数的搜索以及结合模糊搜索等查询方式,将搜索时间压缩到0.5秒以内。
(6)指标可配置
实现项目相似性度量的自适应阈值调整机制、动态定义相似度指标功能。
全文相似性检测系统
在科研领域,每年都有大量的科研项目进行各种申报,这其中也不乏抄袭作假的行为,因此迫切需要一种能在海量文档集中快速、准确、高效地发现相似的文档及相似的内容,检测出项目申请书等材料的抄袭、多次申报和多头申报等现象的有力手段,确保科研诚信及评审的公正公平。
高等院校作为创新人才的聚集地及原始性创新成果的重要源头,是知识创新的主体,知识产出的主力军,是产学研结合的重要组成部分。文章相似性检测行业是一个新兴的产业。伴随着互联网的崛起,以往高校学生在图书馆查阅资料的行为逐步转移到网络上,通过便捷的网络进行查阅相关的信息。正是因为信息查阅的快捷,这把“双刃剑”同时也给在校的一部分学生提供了抄袭的便利,导致了更多高校抄袭事件、学术不端行为的高频率发生。本成果可以广泛应用于高等院校、自然科学基金委、科技厅、专业学会等项目评审单位及大型科研机构,需要对项目申报材料进行查重的单位。
产业化

扫码关注,查看更多科技成果