




- 35 高校采购信息
- 300 科技成果项目
- 6 创新创业项目
- 0 高校项目需求
“仁文伏羲”中文大模型


随着计算能力的提升和大规模文本数据的积累,研究者发现模型规模和预训练数据量对于模型性能具有至关重要的作用。大语言模型通常包含数十亿甚至上千亿的参数,其训练数据涵盖了来自不同领域的大量语料,如书籍、新闻、社交媒体等。这使得大语言模型不仅具备较强的语言理解能力,还能够在许多任务中展现出强大的生成能力。以ChatGPT为代表的大语言模型不仅可以进行对话,还能够写作、编程、回答专业问题,在不同任务中展现了强大的灵活性和高效性,为自然语言处理领域带来了革命性的突破。
大语言模型的主要模型架构为Transformer ,通过自回归语言模型的方式进行训练。训练过程通常包括两部分:预训练和对齐训练。预训练是大语言模型的基础,旨在让模型从无标注的大规模语料库中学习语言内在规律与世界知识。对齐训练使大语言模型生成的输出更符合人类的期望,避免出现道德伦理问题,主要包括监督微调和基于人类反馈的强化学习两个阶段。
然而大语言模型的广泛应用也引发了一系列安全问题,主要体现在内容生成的准确性、伦理问题、隐私泄露以及模型滥用等方面。因此,还需要进行特定的安全对齐训练,防止模型在处理敏感话题时生成有害内容,并增强其在伦理方面的可靠性。
仁文伏羲是由研发团队实验室自主研制的,与中国人文伦理价值对齐的中文大模型。目前1.0版本模型拥有67亿参数,进行了海量中文数据的“自监督学习” (预训练)及大规模指令数据的“模仿学习”(微调),展现了强大的问答、生成、对话、意图捕获、价值对齐等能力。
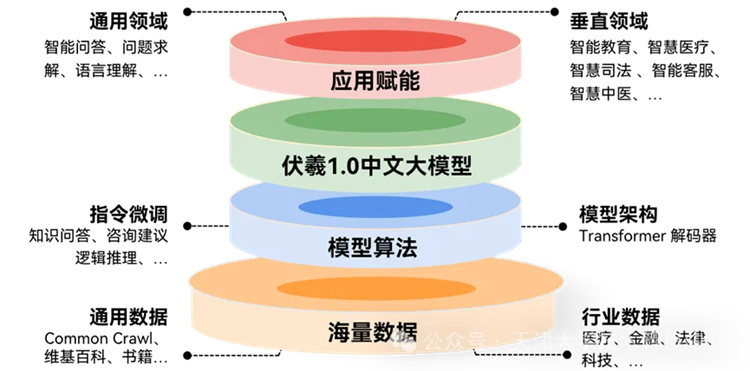
模型采用自主研制路线,在数据、基座模型、对齐训练、大模型评测等方面进行了探索和深入研究,取得了多个创新突破:
(1)建设了TB级大规模中文数据库,研制算法对互联网中文数据进行了深度治理,取其精华,去其糟粕;
(2)从零开始预训练中文ChatGPT类大模型基座,自研了高效的分布式训练算法和通信机制,提出了结构化的混合专家系统模型;
(3)研制了面向中国人文伦理价值的对齐训练数据集及相关算法;
(4)构建了多个中文大模型能力评测及价值对齐评测基准数据集。
随着大语言模型的应用在各行业迅速扩大,模型的安全性和可信性问题日益成为焦点。仇恨言论、虚假信息、隐私泄露等问题使得企业、机构和监管机构对大语言模型的部署持谨慎态度。因此,市场对具备高度安全性和可信性的模型技术需求正在迅速增长,特别是在医疗、金融、法律等对信息准确性和隐私要求极高的领域。
目前,仁文伏羲1.0大模型在多个基准数据集上优于已开源的大模型,部分研究成果将开源,包括开源GB级大规模中文数据集、覆盖70+学科的中文大模型能力评测数据集M3KE、中国传统价值对齐评测数据集等。研发团队实验室自2021年底开始研制中文大模型,继1.0版本之后,还会陆续推出支持中英文的2.0版本,参数规模将达到几百亿级别,3.0版本参数规划在千亿以上。目前1.0版本已逐步开始与多个行业的应用场景进行深度对接,如智慧教育、智慧医疗等,以推动AIGC产业发展,并赋能相关企业。
近年来,大语言模型取得了显著进展,其中最为人们所熟知的有 OpenAI 的 ChatGPT 和 GPT-4 等。这些模型在众多领域如数学、逻辑推理、医学、法律和编程中展现出接近人类的水平。
但随着大语言模型能力的飞速发展,关于它们可能带来的伦理风险和对人类的潜在威胁的担忧也随之增长。大语言模型可传播其训练数据中的有害信息,例如偏见、歧视和有毒内容等。它们可能会泄露训练数据中的私密和敏感信息,或产生误导性和虚假性信息。
未来这些语言代理将越来越多地融入我们的日常生活,任何未对齐行为都可能导致意想不到的后果。因此,需要推动大语言模型对齐技术的研究和突破,使模型的输出和行为与人类的期望和价值相一致。

扫码关注,查看更多科技成果