




- 259 高校采购信息
- 685 科技成果项目
- 12 创新创业项目
- 0 高校项目需求
大模型的软硬件协同优化和高效部署技术


1. 痛点问题
随着人工智能技术的快速发展,特别是近年来深度学习算法和计算机软硬件系统的进步,使得大规模预训练模型成为可能。这类大模型能够执行更为复杂的任务,在文本、图像、视频的生成和理解方面展现出了前所未有的能力,并在多个领域展现出了巨大的应用潜力。然而,大模型的训练和推理需要庞大的算力资源作为支撑,这对于我国人工智能领域的持续高质量发展提出了新的挑战。
当前,国产人工智能大模型的训练和推理部署仍面临着严峻的算力瓶颈。一方面,国产高性能计算平台相较于国际先进水平仍存在一定差距,尤其是在芯片设计与制造领域,高端GPU等关键硬件设备的自主研发能力不足,导致国产算力难以满足日益增长的大模型计算需求;另一方面,由于美国商务部的高端芯片出口禁令等国际贸易环境的不确定性,进一步加剧了国内算力资源的短缺问题。在当前国内外环境下,国内大模型产业链面临的部署成本高、国产芯片替代难、算力缺口大、解决方案不成熟等问题使得人工智能产业的持续高质量发展受到了严重制约,不仅影响了前沿技术的研发进度,也限制了AI技术在各行各业中的广泛应用。
2. 解决方案
本项目提出面向大模型的软硬件协同优化和高效部署技术,利用模型、算法、系统与硬件的跨层协同优化,实现面向异构算力的大模型训练和推理流程的全栈式优化,具体包括:
1)模型层:提出面向大模型训练的参数自动化搜索方法,构建面向大语言模型的文本评测基准,实现大语言模型的高效微调训练系统,显著提高大模型的预训练和微调效率;
2)算法层:提出面向大模型的高效压缩方法,通过稀疏注意力机制、混合精度量化和动态猜测解码方法,降低大模型的计算量和显存代价,在保证算法准确率的前提下提高系统吞吐性能;
3)系统层:提出面向异构硬件的分布式任务动态发现方法,通过基于k8s容器的虚拟化系统实现多用户的大模型分布式高效推理;
4)硬件层:提出面向大模型推理的高效FPGA硬件实现方案,通过指令动态压缩、层归一化协同计算、混合精度稀疏计算架构,实现高能效、高吞吐的大模型推理计算。
预期形成针对算法到芯片、芯片集群到模型、模型到应用的三阶段“M×N”中间层,开发一系列大模型软硬件协同的云-边-端一体化解决方案。
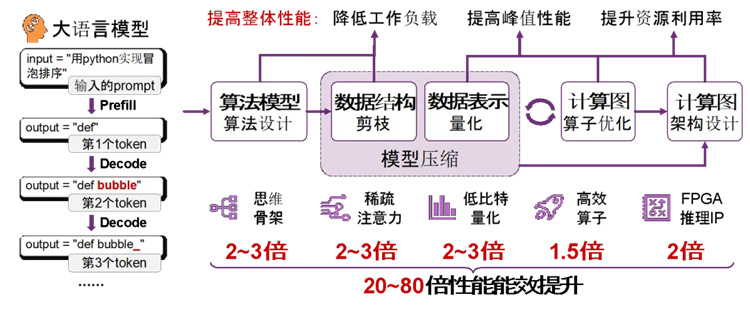
图1. 面向大模型的软硬件协同优化技术,通过降低工作负载、提高峰值性能、提升资源利用率,可实现大模型训推约20——80倍的性能和能效提升
2023年以来,以ChatGPT为代表的大模型的出现标志着一个崭新时代的开启,未来大模型应用将渗入千家万户,并助力全球生产力的跃迁。根据艾瑞咨询的预测,预计到2028年,中国AIGC产业规模将达到7,202亿元。
根据IDC、埃森哲、亿欧、群智咨询等众多机构的分析和预测,中国大模型软硬件一体化优化将具有千亿元/年市场空间,智算云、一体机及端侧芯片数百亿元/年落地路径已基本明晰。
本项目已形成“大模型的软硬件协同优化和高效部署技术”的初步科研成果,未来规划在大模型算法创新、训练/推理软硬件协同优化和大模型推理芯片等技术方向上继续进行研究,并推动成果转化。经初步测算,至2027年,预计国内大模型中间层每年市场规模近1,200亿元,本项目具有良好的市场前景。
本项目成果专注于上游软件和下游芯片硬件的中间层优化适配工作,专注于构建一个高效的软硬件协同优化适配系统,在上游软件和下游芯片硬件之间起到桥梁的作用。通过技术创新,本项目成果使模型训练和推理速度提升1个数量级以上,在提升性能、降低成本、缩短开发周期等方面具有显著优势,为AI产业提供了高效、兼容的解决方案,将在未来市场中发挥重要作用。
虽然目前国内已涌现了大量大模型公司和相关硬件厂商,但从国内外产业发展趋势来看,目前暂无针对多种大模型和多种芯片的软硬件部署平台。各硬件厂商仅支持独立适配大模型,导致单一模型适配几乎很难在不同硬件平台之间进行迁移,且特定模型在特定硬件上进行优化适配仍然需要耗费大量的人力物力时间成本。此外,各个大模型公司要么仅限于研究某一细分领域的优化技术,要么没有针对不同模型和芯片来做适配优化,均无法打通硬件、模型算法层面。

扫码关注,查看更多科技成果