




- 15 高校采购信息
- 635 科技成果项目
- 4 创新创业项目
- 0 高校项目需求
面向垂直应用的高质量检索增强生成大模型服务


大语言模型(Large Language Model, LLM)是一种新兴的人工智能技术,也是人工智域的革命性成果。当前,大语言模型已被应用在文本理解与生成、知识问答、聊天娱乐等各种工作场景,对日常工作生活方式产生了极大的影响。传统的LLM虽然具备强大的文本生成能力,但由于其训练数据是固定的,随着时间推移可能会变得过时,且缺乏提供准确、上下文响应的能力,对一些需要特定领域知识的垂直应用场景的支撑能力不足。检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了LLM和信息检索技术的人工智能技术,通过构建知识检索与问答增强智能体(Agent),利用外挂知识库来增强生成模型的能力,可有效解决生成模型由于训练知识缺乏或过时所带来的局限性,大幅度提升大模型的问答质量,同时有效抑制模型幻觉,保护私有知识产权,在对专业或领域知识需求较高或对信息新鲜程度要求较高的垂直LLM服务系统中的作用尤为突出。
目前,RAG的知识检索过程主要通过使用内容分片和相似度匹配等机制来检索与Query有关的文本片段,该方式虽然可调节知识匹配的范围,但非常容易造成概念混淆、引入无关数据噪声等问题,且难以设置合适的阈值:在相似度阈值要求较低时,所匹配的数据量虽然可能较多,但与答案相关的信息密度很低,造成大量无关信息的污染;阈值较高时则匹配到的知识片段较少,降低回答结果的知识点覆盖面和准确性。此外,由于匹配机制要求对知识库进行分片匹配,会造成匹配结果的信息割裂,导致检索结果完整性很差,对表格等类型的数据的检索能力也较弱。上述问题导致目前主流的基于向量化知识库的垂直RAG服务存框架在知识检索信息密度低、知识碎片化、存在大量无关信息干扰、知识覆盖面窄等问题,对垂直RAG服务的性能造成了非常大的影响,降低用户体验质量。
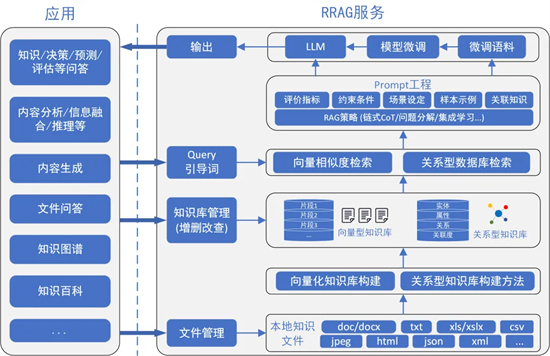
图1 RRAG服务框架
针对上述问题,我校科研团队研发了关系型检索增强生成(Relational RAG,RRAG)框架以实现面向面向垂直应用的大模型服务。RRAG服务框架如图1所示,其核心工作和优势包括以下三个方面:
(1)高质量关系型知识库构建。当前RAG知识库的构建一般采用向量化的方式将语料信息转换为分片段的向量库,为后续知识匹配或查找过程提供支撑。该方式虽然简单,但其未对知识数据进行任何的精炼、提取等过程,对表格等数据的支撑能力很弱,在后续知识匹配查询时效率也较低。为此,RRAG创新性地使用关系型知识库来实现知识检索增强过程,通过将知识文件转换为关系型知识库,从深度、广度、粒度、关联度上提升知识检索结果的质量,为提升RAG智能体服务能力高效、精准的知识检索能力提供根本支撑;
(2)规范、应用面广的RRAG Prompt构造方法。提示词工程(Prompt engineering)是引导大模型给出符合业务需求结果的重要一环。目前,Prompt工程尚未形成统一的规范或模式,而如何设计面向RAG的Prompt设计规范仍是一个开放课题。RRAG构建了一套规范、普适的Prompt设计方法和Prompt生成机制,为最大可能激发LLM的潜力、提升模型输出结果的质量提供Prompt方法支撑;
(3)基于RRAG的大模型低成本微调方法。大模型微调对硬件算力和语料质量的要求较高。在具备充足算力条件的情况下,如何获取高质量RAG训练语料是实现RAG大模型微调的关键。采用人工标注的方式不仅效率低下,成本也非常高,同时语料的多样性也较为欠缺。为此,RRAG可实现针对LLM低成本微调方法,在构建关系型知识库的基础上,可进一步实现RAG训练语料的自动高效生成,无需人力成本,生成语料多样,实现面向RAG服务的大模型的低成本微调过程,进一步增强RRAG的服务质量。
RRAG可支撑丰富的上层应用,包括面向各种需求的内容生成,如知识问答、评估、预测、知识融合、多模态决策等;支持知识图谱应用,可实现关系查询和推理等功能;支持将原始语料内容凝练总结为规范化的知识百科信息。
小试阶段/试用阶段。
RRAG已应用于智慧农业和航空航天相关项目2项,已完成RRAG系统的第一版本的搭建,具备知识问答、评估问答、知识图谱、知识百科、文件问答、模型微调等功能,具备可演示平台。在知识问答场景下,相比于通用的向量型RAG框架,对知识点的覆盖全面性和回答准确性可提升10%以上,甚至更高。
大模型具有非常强大的内容生成、信息融合、逻辑推理、少样本学习等能力,应用得当可有效提升知识获取的智能性和可靠性,并辅助完成知识获取、智能办公、辅助决策、评估诊断、趋势预测等多样化应用。RRAG核心优势在于可有效增强知识检索结果的质量和范围,进而有效提升RAG生成能力,可在上述应用中发挥重要作用。

扫码关注,查看更多科技成果