



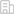

- 16 高校采购信息
- 179 科技成果项目
- 1 创新创业项目
- 0 高校项目需求
ZL-MOVE 卷积神经网络处理器及其开发系统


为了能够使基于卷积神经网络的深度学习技术得以更广泛的应用,需要尽可能地降低其应用系统的设计与开发成本,并使其体积和功耗降至最低。本团队开发设计了一种称之为ZL-MOVE的新型卷积神经网络处理器(NPU)体系架构,该架构基于控制数据传输并触发相关操作的简洁指令及规则的二维阵列并行计算结构,可以非常便捷的实现电路的参量化设计及简单易用的应用程序编译器设计,从而可以达到针对具体应用进行处理器硬件电路和软件编译器定制化设计的目的,从而使系统电路和应用程序设计简单、高效,能够方便地应用于诸如智能传感器和物联网IoT等对体积、重量及功耗要求严格的嵌入式应用领域。
团队设计的ZL-MOVE神经网络处理器采用了将传输触发体系结构TTA 与复杂指令集体系结构CISC相结合的新型的适于边缘计算的并行计算机体系结构,其指令的功能与机器代码格式与TTA指令一致,保持了TTA指令所具备的指令与数据并行操作的特点,而其指令的执行又具有CISC结构多周期执行的特点,非常适用于数据传输与计算密集型的应用。在实际的应用中,ZL-MOVE体系结构的NPU既可以开发程序中指令的并行性,又可以开发数据的并行性,同时指令的多周期执行方式完善了指令的功能和执行效率,并且可以极大地提高处理器的最高工作频率。
下图是ZL-MOVE架构卷积神经网络处理器的结构框图。其设计的核心思路是采用数据传输MOVE指令以DMA数据块传输方式将一组运算数据传送到高速数据缓冲区中,再根据指令中给出的操作目的地址触发相应的多周期操作来实现卷积神经网络中的卷积、池化、残差、非线性函数和全连接等运算操作,而这些操作均通过参数可配置硬件状态机和以2维方式构建的大规模并行处理单元(PE)阵列加以实现。
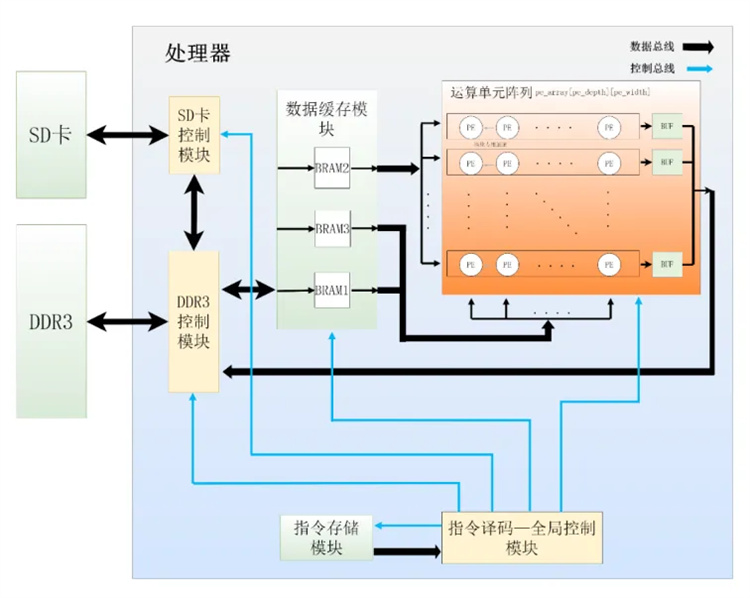
图 1 ZL-MOVE 神经网络处理器结构图
由于ZL-MOVE体系架构NPU的指令功能极为简单,即通过将运算操作数传输至指定的处理单元,并触发该单元完成相应的处理操作,因而可以非常方便的为其设计应用程序编译器以及包括软件虚拟机和系统调试器在内的系统软硬件综合开发调试工具,从而可以大幅降低应用程序的开发和调试难度,提高系统的设计效率。
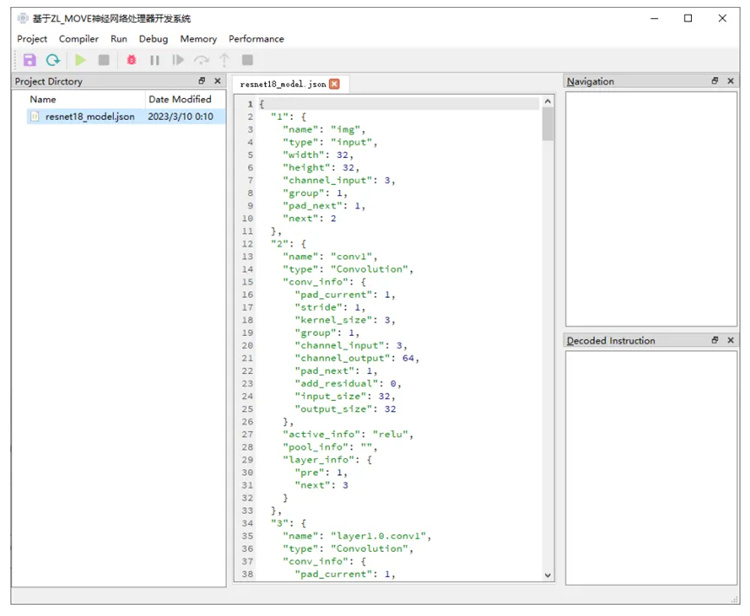
下图是是ZL-MOVE神经网络处理器软硬件综合开发系统的图形化界面,图(a)是软硬件综合开发系统主界面,图(b)是应用程序编译器中卷积神经网络CNN模型参数定义界面,用户通过图形化或JSON格式的CNN结构及参数描述文件即可以输入将要编程实现的CNN模型及其相关参数,编译器据此就可以自动生成完成该网络前向推理运算所需的全部应用程序指令。
(a)软硬件综合开发系统主界面
(b)应用程序编译器 CNN 网络结构定义界面
图 2 ZL-MOVE 神经网络处理器软硬件开发系统图
课题组设计的ZL-MOVE神经网络处理器及其软硬件开发系统已经成功的应用于实际的工程项目中,下图所示是基于上述系统实现的基于模板的深度学习目标检测定位系统实物图,该系统采用Xilinx Kintex-7 XC7K410T FPGA实现,NPU中并行处理单元(PE)数量为1024,可以实现256*256 图幅检测区域的基于模板(图幅32*32)的目标检测和定位,速度可达400帧/秒,当IoU为50%时,检测准确率可达85%以上。系统PCB尺寸为90*96*10mm,重量为78克,系统功耗为4.4W。

图 3 基于 ZL-MOVE 神经网络处理器的应用系统实物图
原理样机

扫码关注,查看更多科技成果